On July 19th 2022, Google introduced Carbon Language. What exactly is Carbon, and what does it aim to achieve? Note that the Carbon coding language is experimental.
To understand Carbon, we first need to take a look at the language it’s attempting to augment. That is, C++. It remains the dominant programming language for performance critical software, and has been a stable foundation for massive codebases. However, improving C++ is extremely difficult. This is due to a few reasons:
- Decades of technical debt
- Prioritizing backwards compatibility over new features
- C++, ideally, is about standardization rather than design
- Uses a committee process that takes multiple years to make changes, and sometimes can’t at all
Carbon, as Google puts it, is okay with “exploring significant backwards incompatible changes”. This has pros for those wanting to work with a language developing with the mindset of “move fast and break things”.
Carbon promises a few things in their readme:
Carbon is fundamentally a successor language approach, rather than an attempt to incrementally evolve C++. It is designed around interoperability with C++ as well as large-scale adoption and migration for existing C++ codebases and developers. A successor language for C++ requires:
- Performance matching C++, an essential property for our developers.
- Seamless, bidirectional interoperability with C++, such that a library anywhere in an existing C++ stack can adopt Carbon without porting the rest.
- A gentle learning curve with reasonable familiarity for C++ developers.
- Comparable expressivity and support for existing software’s design and architecture.
- Scalable migration, with some level of source-to-source translation for idiomatic C++ code.
Google wants Carbon to fill an analogous role for C++ in the future, much like TypeScript or Kotlin does for their respective languages.
JavaScript → TypeScript
Java → Kotlin
C++ → Carbon?
Talk is cheap, show me the code
Okay, so what does Carbon look like then?
First, let’s see how to calculate the area of a circle in C++.
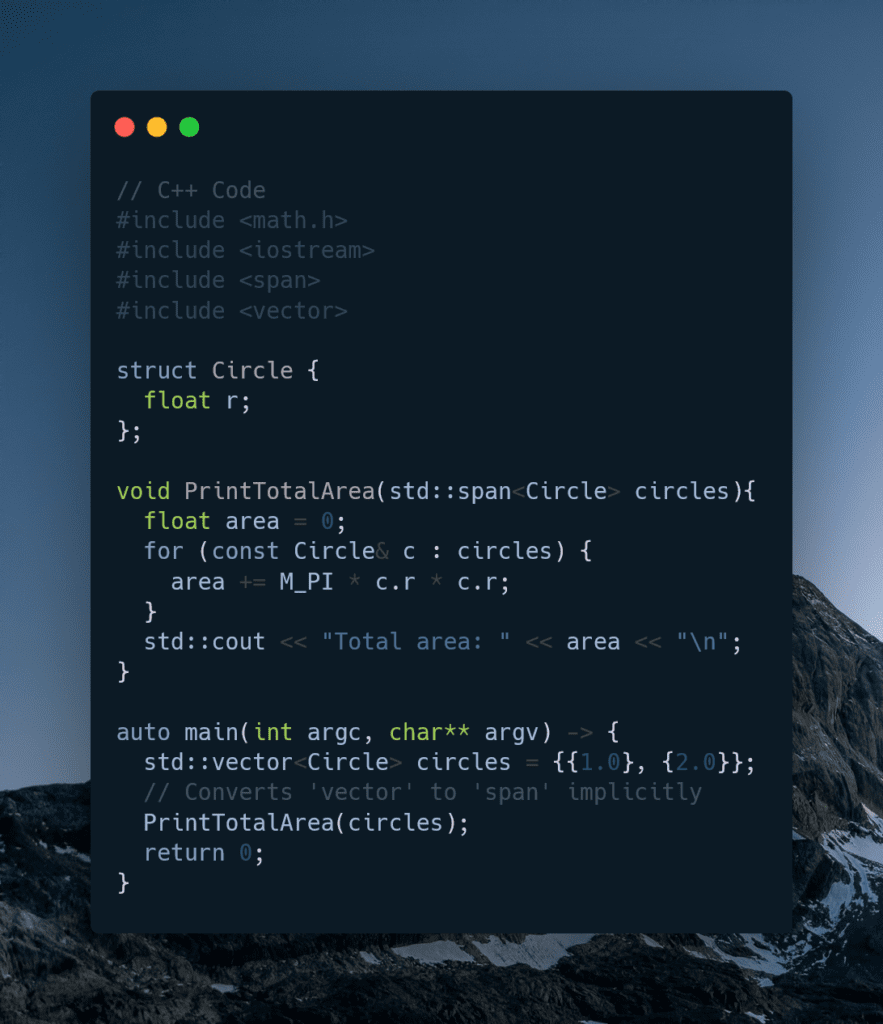
Compared to Carbon:
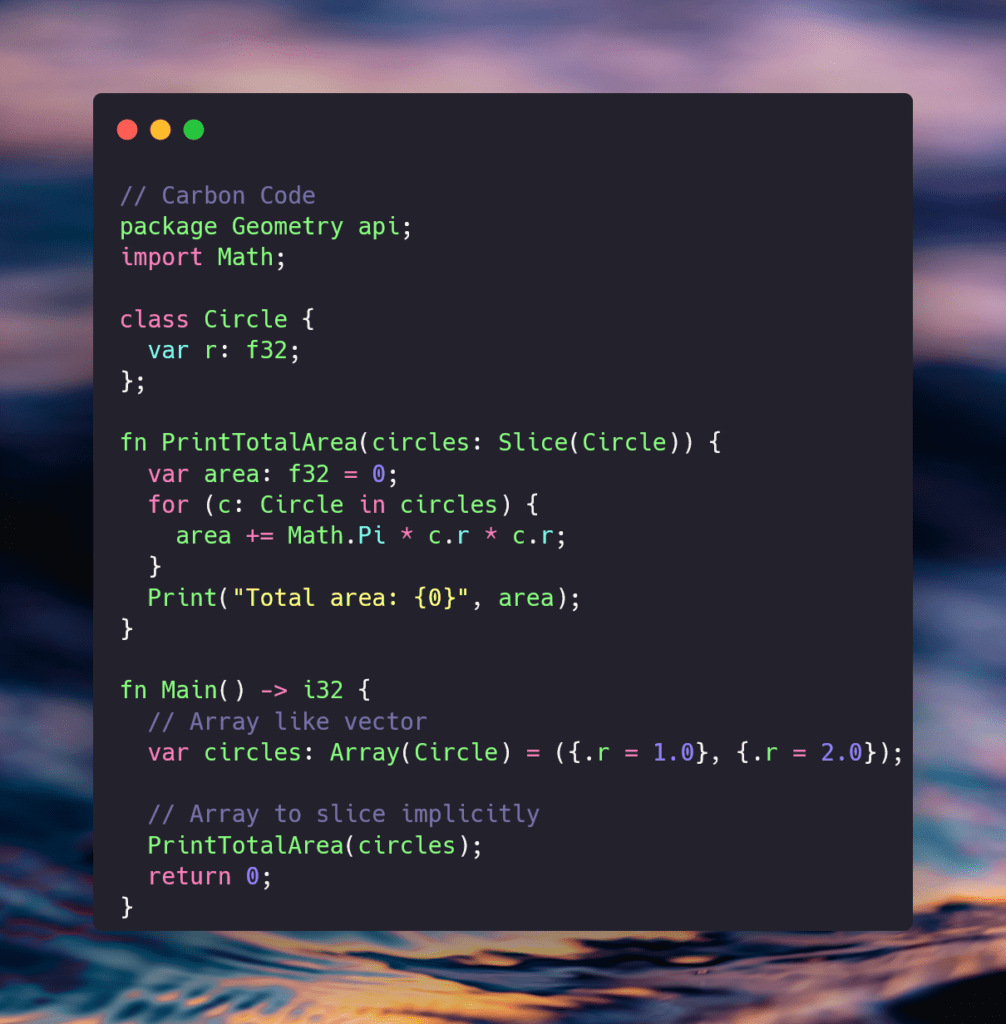
My initial thoughts are that the syntax looks mixed between C#, JavaScript, and C++. Prepending “var” before each variable seems redundant. Why not a type name followed by a declaration? One might argue that it leads to easy variable identification without memorization of variable types but that makes little sense as you put the type anyway. The way variables are initialized with “:” instead of =, reminds me of Javascript. Not sure if that’s a good thing, it looks less like C++ than I expected. Oddly, they chose “import” for the system packages it seems which is also shared with Python. I do like the shortening of function to fn. You could argue shorthand is the point because it’s cleaner and smaller, but again why is it defined as a function and then an ‘i32’? Seems redundant. unless they decided fn FunctionName() -> i32 is shorter than int FunctionName(). It could be their goal is simply to separate the syntax from other known languages enough to recognize at a glance. Maybe I’m missing something.
One neat feature they’ve shown is the interoperability between Carbon and C++. You can call C++ from Carbon and vice versa. You can rewrite or replace as little or as much of your libraries as you want without fear of breaking anything. Well, at least without breaking anything more than normal when dealing with C++.
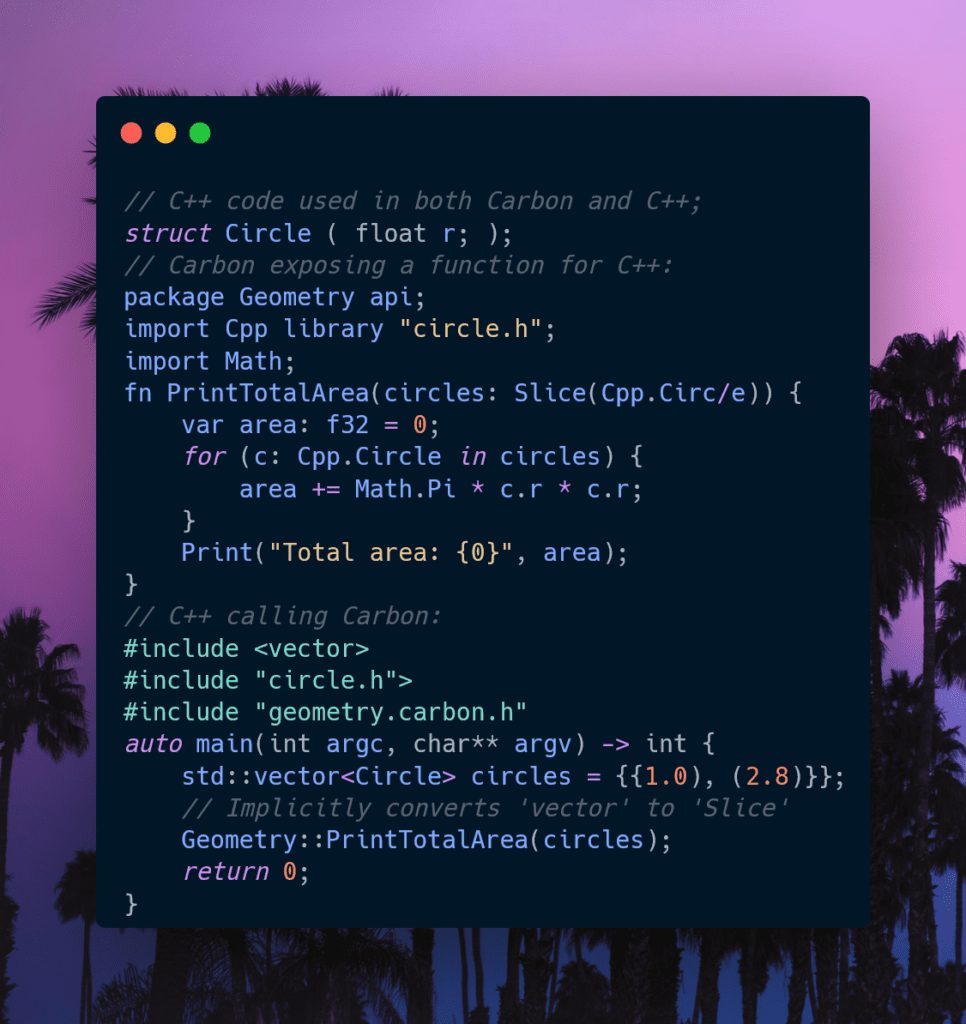
And better memory safety is also promised
Safety, and especially memory safety, remains a key challenge for C++ and something a successor language needs to address. Our initial priority and focus is on immediately addressing important, low-hanging fruit in the safety space:
- Tracking uninitialized states better, increased enforcement of initialization, and systematically providing hardening against initialization bugs when desired.
- Designing fundamental APIs and idioms to support dynamic bounds checks in debug and hardened builds.
- Having a default debug build mode that is both cheaper and more comprehensive than existing C++ build modes even when combined with Address Sanitizer.
Time will tell if the language develops into a developer favorite or fades into obscurity like Dlang. What, you haven’t heard of D?
It helps me if you share this post
https://rose.dev/blog/2022/08/03/carbon-coding-language-googles-experimental-successor-to-c/
Published 2022-08-03 00:19:33